MAR: Masked Autoencoders for Efficient Action Recognition
摘要
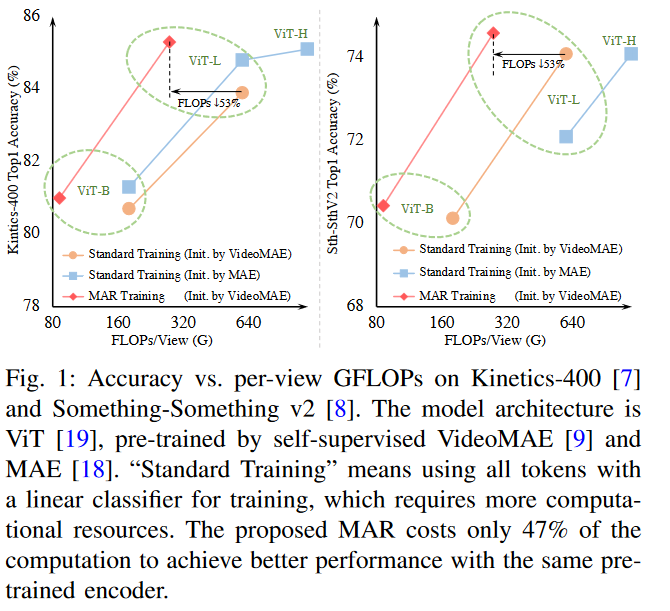
标准的视频行为识别方法通常是在全输入视频上进行的,由于视频中广泛存在的时空冗余,这种方法是低效的。最近在掩蔽视频建模方面的进展,即VideoMAE,已经显示了香草视觉转换器( ViT )的能力,可以在仅给定有限视觉内容的情况下补充时空上下文。受此启发,我们提出了隐藏行为识别( Masked Action Recognition,MAR ),通过丢弃一部分patches和只对一部分视频进行操作来减少冗余计算。MAR包含以下两个不可或缺的组件:单元运行掩码和桥接分类器。具体来说,为了使视觉里程计更容易地感知到可见patches之外的细节,提出了单元运行掩码来保留视频中的时空相关性,即保证了同一空间位置的patches可以依次被观察,便于重构。此外,我们注意到,虽然部分观察到的特征可以重建语义明确的不可见patches,但它们并不能实现准确的分类。为了解决这个问题,本文提出了一个桥接分类器来桥接用于重建的ViT编码特征和专门用于分类的特征之间的语义鸿沟。我们提出的MAR将ViT的计算成本降低了53 %,并且大量的实验表明,MAR始终优于现有的ViT模型,并且具有显著的差距。特别地,我们发现MAR训练的ViT - Large在Dynamics - 400和Something - Something v2数据集上的表现都优于标准训练方案训练的ViT - Huge,而ViT - Large的计算开销仅为ViT - Huge的14.5 %。代码和模型将在此提供。
介绍
近年来,深度神经网络[ 1 ] ~ [ 6 ]在多个大规模视频数据集上的行为识别任务中取得了令人印象深刻的性能[ 7 ] [ 8 ]。这些方法通常依赖于完整的视频帧来理解视觉内容。虽然这样可以获得不错的性能,但由于视频中视觉信息的过度和广泛存在的时空冗余[ 9 ] - [ 13 ],完整视频上的计算是高度冗余的。鉴于此,先前的一个分支提出了通过训练一个额外的模型来减少时空冗余,以专注于相关帧[ 12 ] - [ 17 ]或时空区域[ 10 ],[ 11 ],这可以显著降低计算成本。然而,它们大多需要复杂的操作,例如强化学习和多阶段训练。
在自监督视频表示学习中,掩码自编码器( Masked自编码器,MAE ) [ 9 ] [ 18 ]舍弃了高比例的视觉块,产生了非平凡且有意义的自监督重建任务。香草视觉转换器( Vanilla Vision Transformers,ViT )的简单掩蔽策略可以实现逼真的重建结果[ 9 ],[ 18 ],这意味着视频中被掩蔽的视觉信息可以从有限的可见内容中得到补充,ViT显示了这种能力。这是可能的,因为视频中的时空冗余使模型能够从可见的上下文中推导出不可见部分的视觉语义。经过预训练后,模型在下游动作识别任务上按照标准方案进行微调,该方案将视频的所有细节输入到ViT中。
在本工作中,我们认为,鉴于ViT在仅有有限视觉内容的情况下重建视觉语义的强大能力和视频中的高时空冗余性,操作完整视频帧的标准动作识别方案是非常低效的。为此,我们提出了一种简单且计算高效的端到端方案用于动作识别任务,称为掩蔽动作识别( Masked Action Recognition,MAR )。MAR的核心思想是舍弃一部分视频块以减少ViT的编码令牌,这样可以在一定程度上避免冗余计算。我们从两个角度对此进行了研究:( i )为ViTs设计一个合适的具有强时空相关性的输入掩蔽图;( ii )增加ViTs输出特征的抽象层次。