推流到服务器
优点:用户可以实时看得到视频(既可以检测摔倒,又可以查看家中状况)
缺点:隐私(但是公共场合可以不谈论这些),推流使用的服务器的视频传输速率需要比较大,配置要求比 较高。
使用p2p的推送视频流方案
优点:保护隐私的同时又可以实时观看监控。
缺点:不适用于大规模的情况,公共场合有所不便。
如果部署在终端
优点:可以在本地完成视频处理不必传输到服务器进行处理,即保护隐私又可以检测。
缺点:价格较为昂贵。
将之前收集的视频进行与ntu中的数据结合。
一样站着,坐着,坐下,站起,躺下,摔倒
每个动作的数据集长度应该与时间卷积的卷积范围相近,然后将其组合为时间卷积跨度的一样的一个数组。作为骨架的数据集,利用yolov8x-pose提取骨架并保存。需要准备两个版本一个版本是去掉头部的,另一个版本是全身的。
方案一:测试试利用ntu的骨架信息直接作为输入(由NTU训练的st-gcn++),RGB图像由yolov8处理。
方案二:利用yolov8x-pose提取的骨架信息及 coco 2017 keypoint(去掉头部)的序列去训练st-gcn++, RGB流信息从yolov8中提取。
而RGB流应该是其骨架的中间帧。怎么保存中间帧呢?一个队列?
NTU骨架序列示例图,如下所示:

pyskl中的sgn是st gcn++。
RGB流可不可以采用将多个RGB帧融合的策略,即采用个策略压缩多个RGB帧为一个特征图。(难道还得是注意力?)
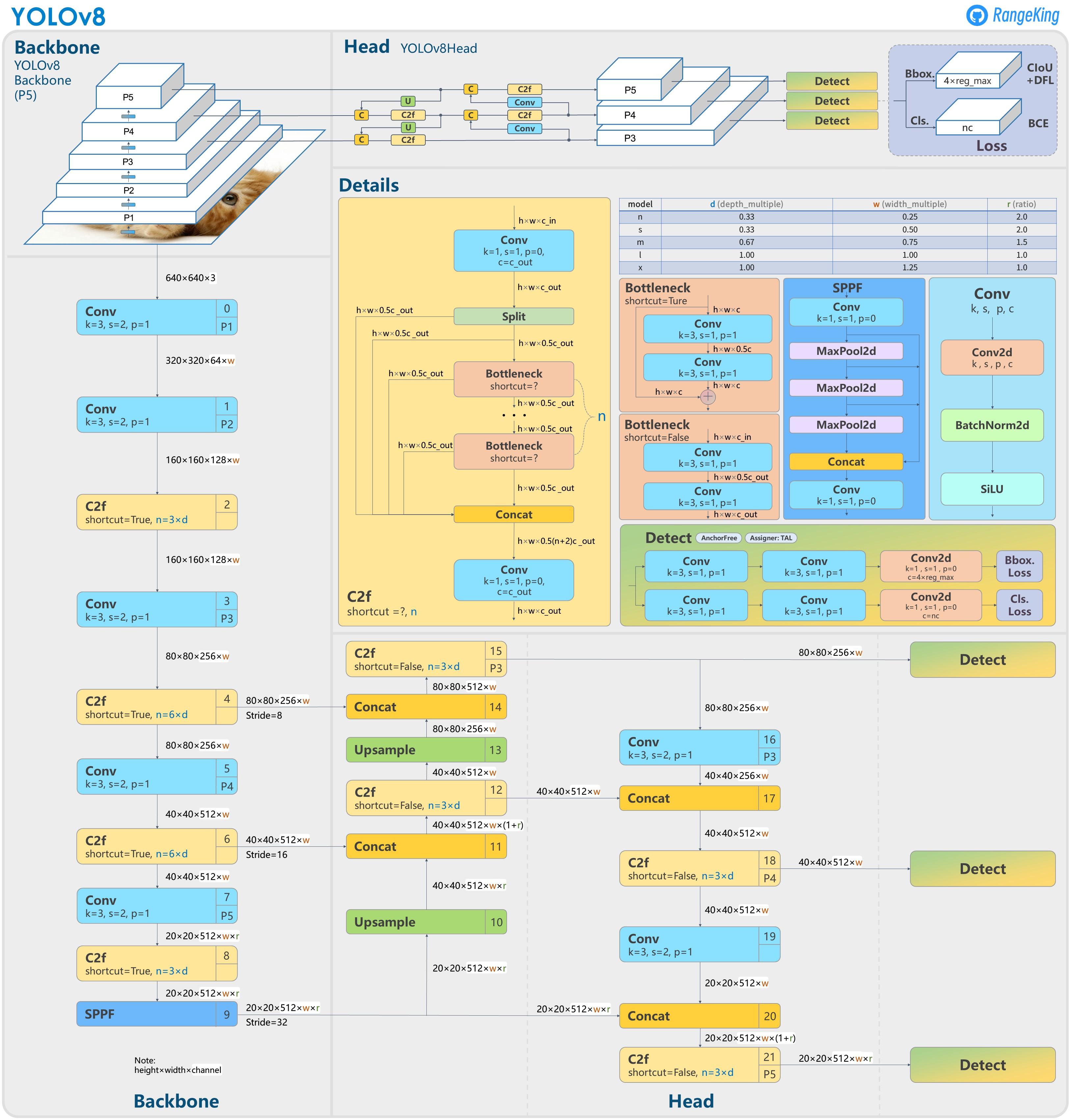
选用了第11层的输出作为从yolov8中提取的特征图
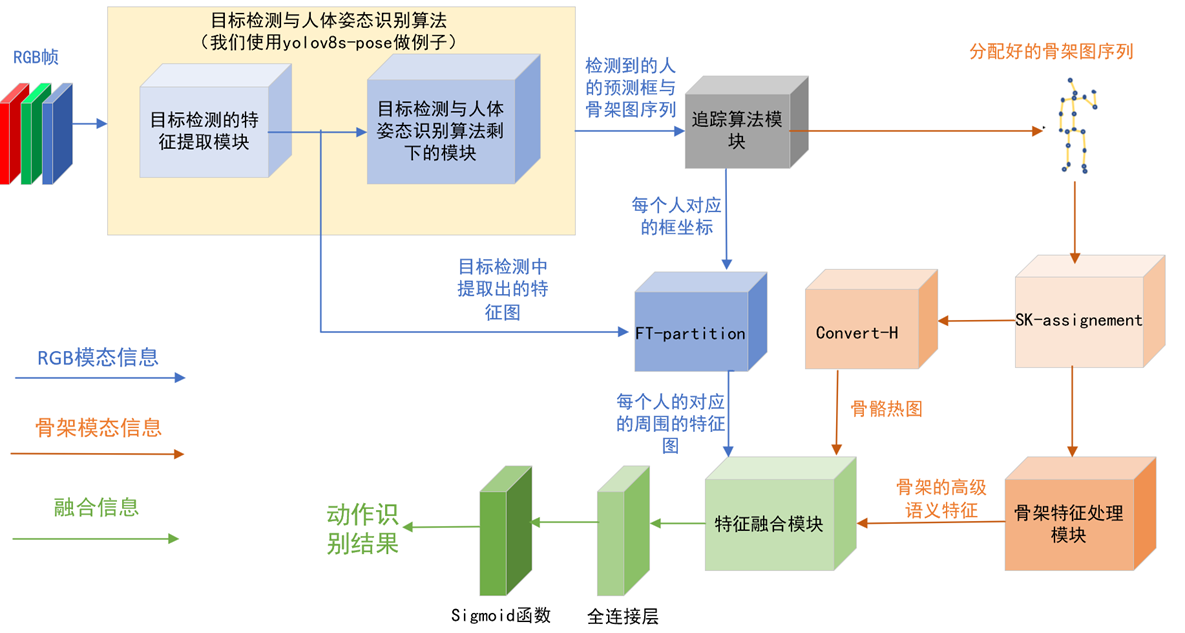
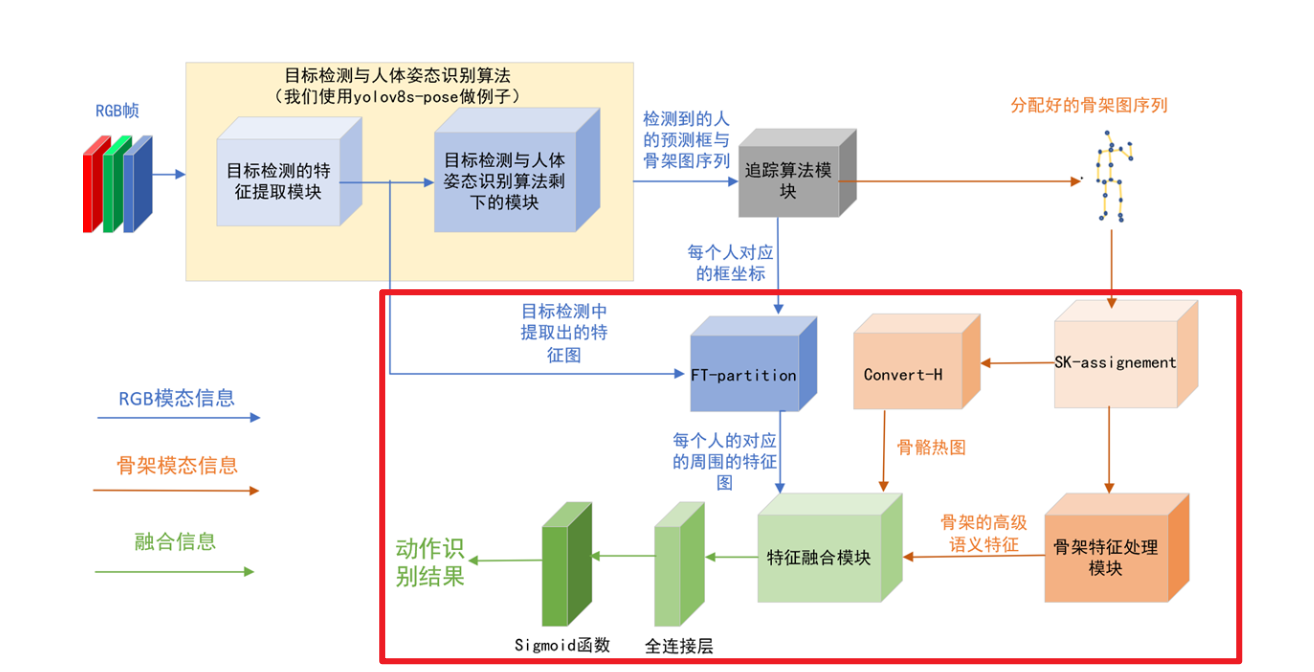
sk-assignment
一起卷积呢?
还是乘好呢?
训练方法考虑
先训练yolov8和基于shift改进的st-gcn++。
再使用利用前面部分的模块得到数据集的结果再训练特征融合模块。
既有骨架又有RGB的数据集(骨架没有缺失):
将骨架的输入改为数据集的骨架的输入
图片则交给yolov8提取信息
只有图片的
输入给图片剩下交给yolov8
yolov8n-pose shift_gcnpp 速度如下:
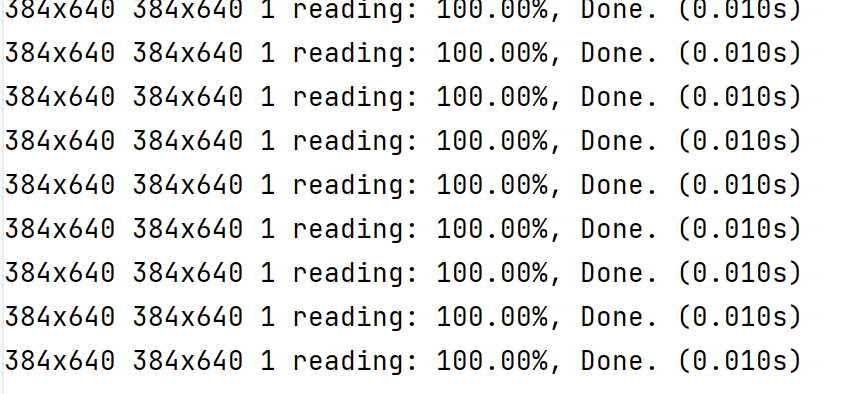
yolov8n-pose.pt stgcnpp 速度如下:
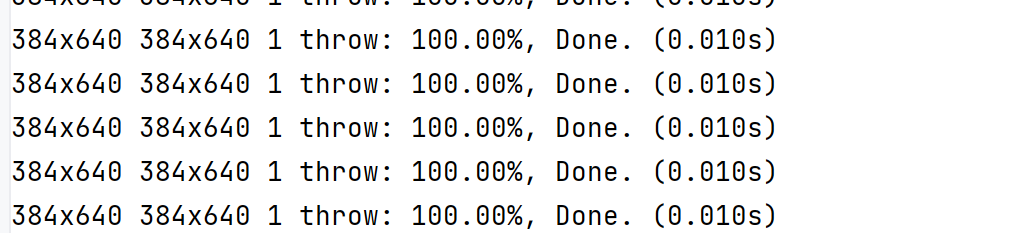
两者差异不大:
shift-gcnpp只能在nvidia的gpu上运行(要有cuda)
运行结构
(模型结构):
传入特征图->yolo->bytetraker(FT-partition)
可能可以使用稀疏矩阵计算
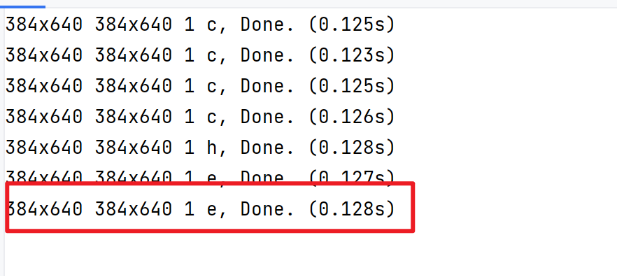
yolov8x-pose-p6版的MISNET,中间帧层为12,中间帧通道数为657。
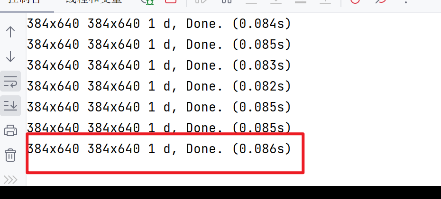
yolov8n-pose版的MISNET,中间帧层为12,中间帧的通道数为145。
[ A 43: falling down,A 9: stand up,A 12: writing,A 27 jump up,A 28 : phone call,A 8: sit down,A 6 : pick up A 29 : play with phone ]
3.9
老师建议1:
去掉早期融合那个分支
或者在建立热图的时候增加权重使得最近帧的权重更大。
老师建议2:
把数据集整合为摔倒和不是摔倒
老师建议3:
交叉注意力等特征融合模块
老师建议4:
剪模型,跳帧,
追踪算法太慢
covert_h_numba,在cpu上做加速更快
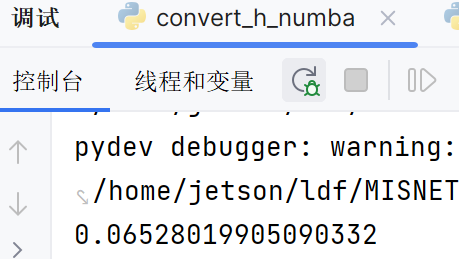
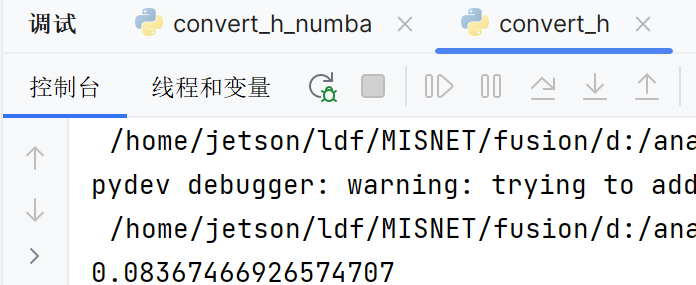
原本的陈锐写的只在cpu上面的
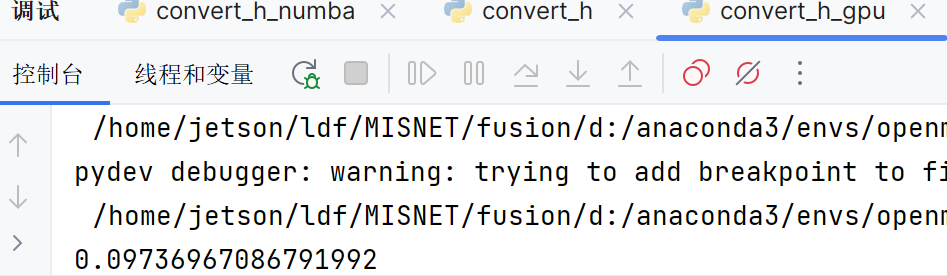
nuomba加gpu的
应该热图形式比较好,因为可以依赖姿态识别程度较低