个人总结
简介
使用骨骼数据的动作识别在计算机视觉中引起了更多的关注。最近,将人体骨骼建模为时空图的图卷积网络(GCNs)获得了显着的性能。然而,基于GCN的方法的计算复杂度相当高,一个动作样本的计算复杂度通常超过15个GFLOP。最近的作品甚至达到了∼100 GFLOP。另一个缺点是空间图和时间图的感受域都不灵活。虽然一些作品通过引入增量自适应模块来增强空间图的表现力,但其表现仍然受到规则GCN结构的限制。在本文中,我们提出了一种新的移位图卷积网络(Shift-GCN)来克服这两个缺点。我们的 Shift-GCN 不使用繁重的常规图卷积,而是由新颖的移位图运算和轻量级逐点卷积组成,其中移位图运算为空间图和时态图提供了灵活的感受场。在三个基于骨架的动作识别数据集上,提出的Shift-GCN明显超过了最先进的方法,计算复杂度降低了10倍以上。
介绍
在计算机视觉领域,基于骨骼的人体动作识别因其在动态环境和复杂背景下的鲁棒性而备受关注[2, 12, 14, 16, 20, 21, 23–25, 27, 30, 34, 36]。
早期的方法[2,3,27]只是使用关节坐标来形成特征向量,很少探索身体关节之间的关系。随着深度学习的发展,研究人员手动将骨架数据构建为伪图像[5,7,10,14]或坐标向量序列[2,16,19,35,36],将其输入CNN或RNN以生成预测。最近,Yan等人[34]提出ST-GCN使用图卷积网络(GCNs)对骨架数据进行建模,GCN包含空间图卷积和时间图卷积。ST-GCN的许多变体被提出[9,12,20–22,31],这些变体通常引入增量模块以增强表达能力和网络容量。
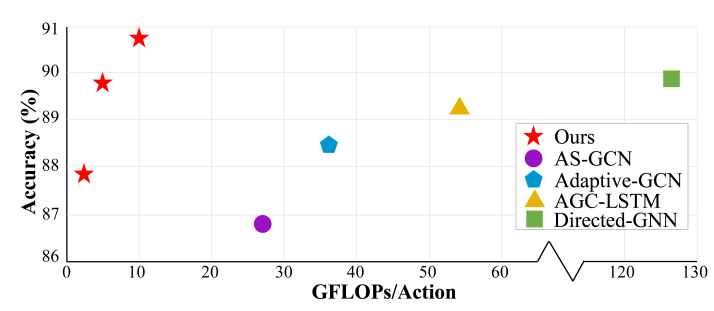
图1. 在 NTU RGB+D X-sub 的GFLOPs vs. accuracy。
然而,这些基于GCN的方法有两个缺点。(1)计算复杂度过重。例如,ST-GCN [34] 一个动作样本的成本为 16.2 GFLOPs1。由于引入了增量模块和多流融合策略,最近的一些工作甚至达到了∼100 GFLOPs [20]。(2)空间图和时间图的感受野都是预先定义的启发式。尽管[20,21]使空间相邻矩阵可学习,但我们的实验表明,它们的表达能力仍然受到规则空间GCN结构的限制。
在本文中,我们提出了移位图卷积网络(Shift-GCN)来解决这两个缺点。我们的 ShiftGCN 的灵感来自移位 CNN [4, 32, 37],它使用轻量级移位操作作为 2D 卷积的替代方案,并且可以通过简单地改变移位距离来调整感受野。提出的Shift-GCN由空间移位图卷积和时间移位图卷积组成。
对于空间骨架图,我们提出了一种空间移位图操作,将信息从相邻节点转移到当前卷积节点,而不是使用具有不同相邻矩阵的三个GCN来获得足够的感受野[9,12,20–22,31]。通过将空间移位图操作与逐点卷积交错,可以在空间维度和通道维度上混合信息。具体来说,我们提出了两种空间移位图运算:局部移位图运算和非局部移位图运算。对于局部移位图操作,感受野由主体物理结构指定。在这种情况下,不同的节点具有不同数量的邻居,因此分别为每个节点设计了本地移位图操作。然而,局部移位图运算有两个缺点:(1)感受野是启发式预定义和局部化的,不适合对骨架之间的多样化关系进行建模。(2)由于不同节点的移位操作不同,部分信息被直接丢弃。为了解决这两个缺点,我们提出了一种非局部移位图运算,使每个节点的感受野覆盖完整的骨架图,自适应地学习关节之间的关系。广泛的消融研究表明,即使常规空间图卷积的相邻矩阵是可学习的,我们的非局部移位图卷积也优于常规空间图卷积[20,21]。
对于时间骨架图,图是通过连接时态维度上的连续帧来构造的。我们没有使用常规的一维时间卷积[9,12,20,21,34],而是提出了两种时间移位图操作:朴素时间移位图操作和自适应时间偏移图操作。朴素时移图运算的感受场是手动设置的,这对于时间建模不是最优的:(1)不同的层可能需要不同的时空感受野[11,33,38]。(2)不同的数据集可能需要不同的时间感受野[11]。这两个问题也存在于常规的一维时间卷积中,其内核大小是手动设置的。我们的自适应时间偏移图操作通过自适应调整感受野来解决这两个问题。广泛的消融研究表明,我们的自适应时间移位图卷积以高效率优于常规时间卷积。
为了验证我们提出的模型的优越性,即时空移位图卷积网络(ShiftGCN),在三个数据集上进行了广泛的实验:NTU RGB+D [19],NTU-120 RGB + D [15]和Northwestern-UCLA[29]。我们在所有三个数据集上都明显超过了最先进的方法,计算成本降低了 10× 以上。NTU RGB+D的GFLOPs与精度关系图如图1所示。
我们的贡献可以总结如下:(1)我们提出了两种空间骨架图建模的空间移位图运算。我们的非局部空间移位图运算计算效率高,性能强。(2)提出了两种时间骨架图建模的时间移位图运算。我们的自适应时移图运算可以自适应地调整感受野,并且以更低的计算复杂度优于常规时间模型。(3)在三个基于骨骼的动作识别数据集上,所提出的Shift-GCN超过了最先进的方法,计算成本降低了10×以上。代码将在以下位置提供:https://github.com/kchengiva/ Shift-GCN.
正文前书
在本节中,我们简要概述了以前基于 GCN 的骨架动作识别模型和 CNN 中的移位模块。
基于GCN的骨架动作识别
图卷积网络(GCN)已成功用于对骨架数据进行建模[9, 12, 20–22, 31, 34]。在这些方法中,骨架数据表示为具有 N 个关节和 T 帧的时空图 G =(V,E)。人类行为的骨架坐标可以表示为 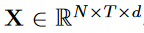 ,其中 d 是关节坐标的维度。基于GCN的模型包含两部分:空间图卷积和时间图卷积。
,其中 d 是关节坐标的维度。基于GCN的模型包含两部分:空间图卷积和时间图卷积。
对于空间图卷积,相邻的关节集定义为相邻矩阵 A ∈ {0, 1}N×N 。为了指定图卷积的空间位置,相邻矩阵通常分为 3 个分区:1) 向心组,其中包含更靠近骨架中心的相邻节点;2)节点本身;3)否则为离心组。对于单个帧,设 F ∈ RN×C 和 F′ ∈ RN×C′ 分别表示输入和输出特征,其中 C 和 C′ 是输入和输出特征维度。图卷积的计算公式为:
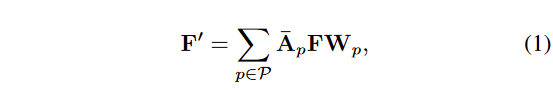
其中 P ={根、向心、离心} 表示空间分区,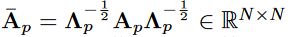 是归一化的相邻矩阵,
是归一化的相邻矩阵,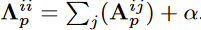 . α 设置为 0.001 以避免空行。
. α 设置为 0.001 以避免空行。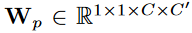 是每个分区组的 1 × 1 卷积的权重。
是每个分区组的 1 × 1 卷积的权重。
对于时间维度,由于时间图是通过连接连续帧构建的,因此大多数基于 GCN 的模型 [9, 20, 21, 31, 34] 在时间维度上使用常规一维卷积作为时间图卷积。内核大小表示为 kt,通常设置为 9。
但是,这些基于GCN的模型有两个缺点:(1)计算成本太重。例如,ST-GCN [34] 一个动作样本的成本为 16.2 GFLOP,包括空间图卷积的 4.0 GFLOP 和时间图卷积的 12.2 GFLOP。ST-GCN的一些近期变种甚至重至∼100 GFLOPs[20]。(2)空间图和时间图的感受野都是预先定义的。尽管一些工作[20,21]使相邻矩阵可学习,但我们的实验表明,其表达能力仍然受到规则GCN结构的限制。
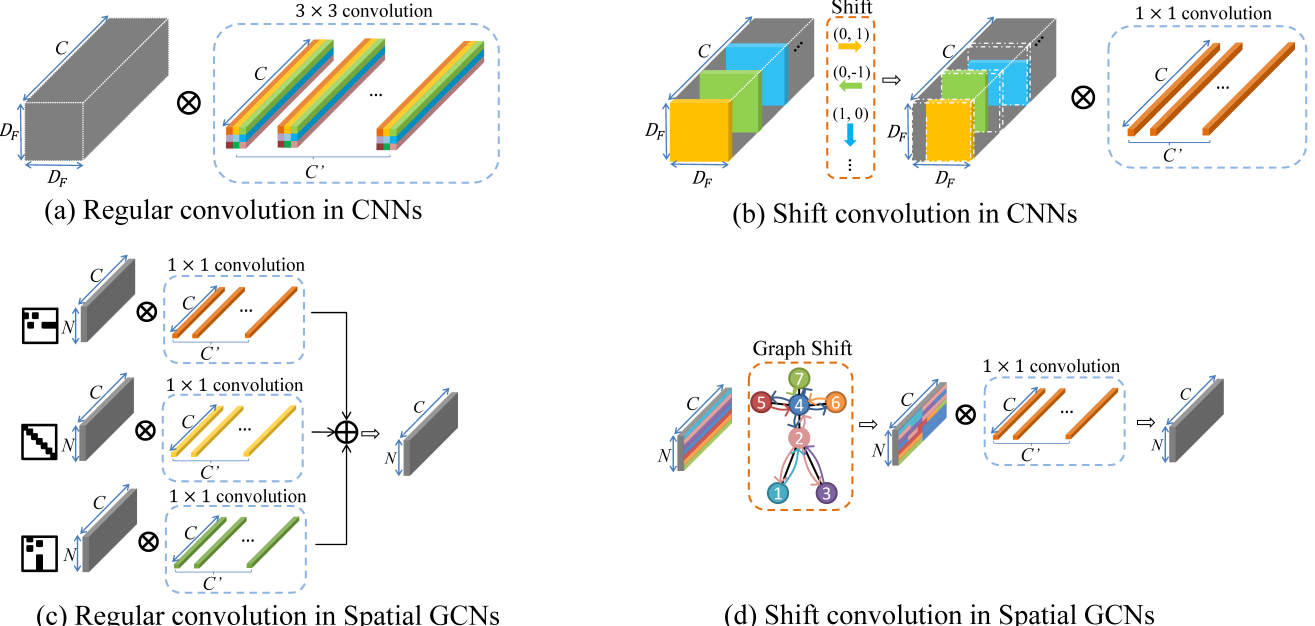
图2.常规卷积(a),CNN中的移位卷积(b)和空间GCN中的常规卷积(c)的图。我们的空间移位图卷积如图(d)所示。
Shift CNNs
设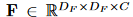 表示输入特征,其中
表示输入特征,其中 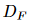 是特征映射大小,C 是通道大小。如图 2 (a) 所示,常规卷积核是张量
是特征映射大小,C 是通道大小。如图 2 (a) 所示,常规卷积核是张量 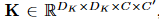 ,其中 DK 是核大小。常规卷积的 FLOP 为
,其中 DK 是核大小。常规卷积的 FLOP 为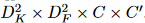 。
。
移位卷积[32]是CNN中常规卷积的有效替代方案。如图2(b)所示,移位卷积由两个操作组成:(1)在不同方向上移位不同的通道;(2)应用逐点卷积来跨通道交换信息。移位卷积的 FLOP 为 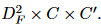 。
。
移位卷积的另一个优点是感受野的灵活性。移位卷积可以通过简单地增加移位距离来扩大其感受野,而不是使用更大的卷积核和增加计算成本。**设每个通道的移位值表示为一系列向量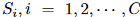 **,其中
**,其中 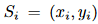 表示二维移位向量。移位卷积的感受场可以表示为每个移位向量在相反方向上的并集:
表示二维移位向量。移位卷积的感受场可以表示为每个移位向量在相反方向上的并集:
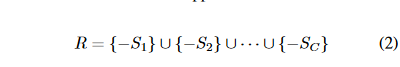
例如,如果xi∈{−1, 0, 1}, yi ∈ {−1, 0, 1},则感受野扩大到3×3。
移位图卷积网络
通过上面的讨论,它促使我们将轻量级移位操作引入到基于GCN的重型动作识别模型中。在本节中,我们提出了移位图卷积网络,其中包含空间移位图卷积和时间移位图卷积。
空间移位图卷积
引入从CNN到GCN的转换操作具有挑战性,因为图形特征不像图像特征图那样有序。在本小节中,我们首先讨论从CNN到空间GCN的类比。 基于这些分析,我们提出了空间骨架图的空间移位图卷积。
从CNN到GCN的类比
CNN 中的常规卷积内核可以被视为几个逐点卷积内核的融合,其中每个内核在指定位置运行,如图 2 (a) 所示,颜色不同。例如,一个 3 × 3 卷积内核是 9 个逐点卷积核的融合,其中每个逐点卷积内核分别在“左上”、“上”、“右上”、“…”、“右下”上运行。
同样,空间 GCN 中的规则卷积核是 3 个逐点卷积核的融合,每个核在指定的空间分区上运行,如图 2 (c) 所示,颜色不同。如第2.1节所述,空间分区由3个不同的相邻矩阵指定,分别表示“向心”、“根”、“离心”。
CNN 中的移位卷积包含一个移位运算和一个逐点卷积核,其中感受野由移位操作指定,如图 2 (b) 所示。
因此,移位图卷积应包含移位图运算和逐点卷积,如图 2 (d) 所示。移位图操作的主要思想是将邻居节点的特征转移到当前的卷积节点。具体来说,我们提出了两种移位图卷积:局部移位图卷积和非局部移位图卷积。
局部移位图卷积
对于局部移位图卷积,感受野由人体的物理结构指定,该结构由骨骼数据集预定义。在此设置中,移位图操作在主体物理图的相邻节点之间执行。
由于身体关节之间的连接不像CNN特征那样井然有序,因此不同的节点具有不同数量的邻居。设 v 表示一个节点,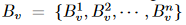 表示其相邻节点的集合,其中 n 表示 v 的相邻节点数。我们将节点 v 的通道平均划分为 n + 1 个分区。我们让第一个分区保留 v 的特征。其他 n 个分区从
表示其相邻节点的集合,其中 n 表示 v 的相邻节点数。我们将节点 v 的通道平均划分为 n + 1 个分区。我们让第一个分区保留 v 的特征。其他 n 个分区从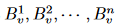 分别。设
分别。设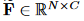 表示单个帧的特征
表示单个帧的特征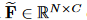 表示相应的移位特征。我们在 F 的每个节点上运行移位操作。
表示相应的移位特征。我们在 F 的每个节点上运行移位操作。
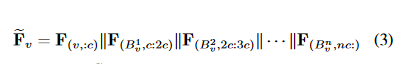
其中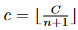 ,F 的索引采用 Python 的索引方式,‖ 表示通道级串联。
,F 的索引采用 Python 的索引方式,‖ 表示通道级串联。
为了说明局部移位图操作的直观性,我们使用 7 个节点和 20 个通道的微小图特征作为实例,如图 3 (a) 所示。我们使用节点 1 和节点 2 作为两个示例。对于节点 1,它只有一个邻居节点,因此其通道分为两个分区。第一个分区保留节点 1 的功能,而第二个分区从节点 2 移位。对于另一个示例,节点 2 具有三个相邻节点,因此其通道分为四个分区。第一个分区保留节点 2 的功能,而其他三个分区从节点 1、节点 3、节点 4 移位。
移位操作后的特征如图3(a)所示。在移位特征中,每个节点从其感受野获取信息。通过将局部移位图运算与逐点卷积相结合,我们得到了局部移位图卷积。
非局部移位图卷积
局部移位图卷积有两个缺点:(1)某些信息未被利用。对于图 3 中的示例
(a),节点 3 中最后四分之一的通道在移位操作期间直接被丢弃。这是因为不同的节点具有不同数量的邻居。(2)最近的研究表明,仅考虑局部连接并不是骨骼动作识别的最佳选择[12,20,21,31]。例如,两只手之间的关系对于识别“拍手”和“阅读”等动作很重要,但两只手在身体结构中彼此相距甚远。
我们提出了一个简单的解决方案来解决这两个缺点:使每个节点的感受野覆盖完整的骨架图。我们称之为非局部移位图操作。
非局部移位图操作如图 3 (b) 所示。给定一个空间骨架特征图F ∈ RN×C,第 i 个通道的移位距离为 i mod N。移出的通道用于填充相应的空白空间。节点 1 和节点 2 的移位操作作为示例所示。在非局部移位之后,特征看起来像一个螺旋,这使得每个节点从所有其他节点获取信息,如图 3 (b) 所示。通过将非局部移位图运算与逐点卷积相结合,我们得到了非局部移位图卷积。
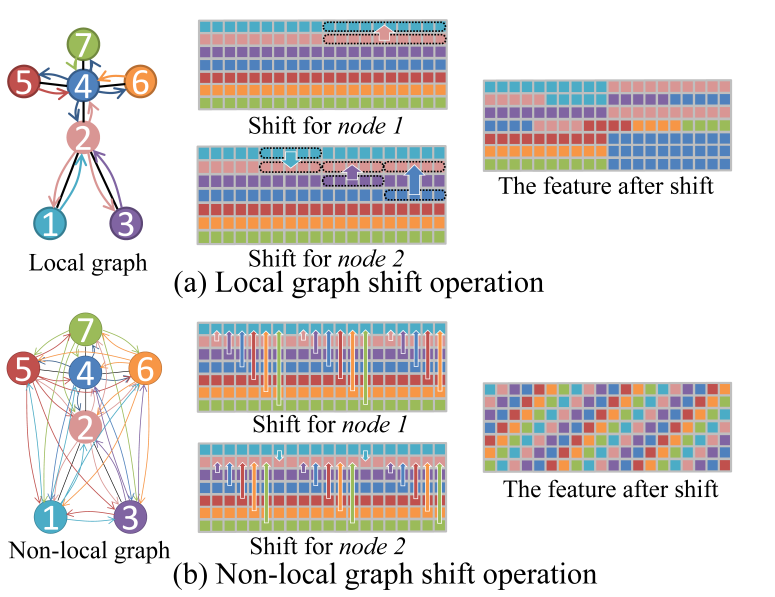
在非局部移位图卷积中,不同节点之间的连接强度是相同的。但人类骨骼的重要性是不同的。因此,我们引入了一种自适应非局部移位机制。我们计算移位特征和可学习掩码之间的元素乘积:
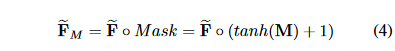
M指的是特征的掩码:可学习的参数矩阵
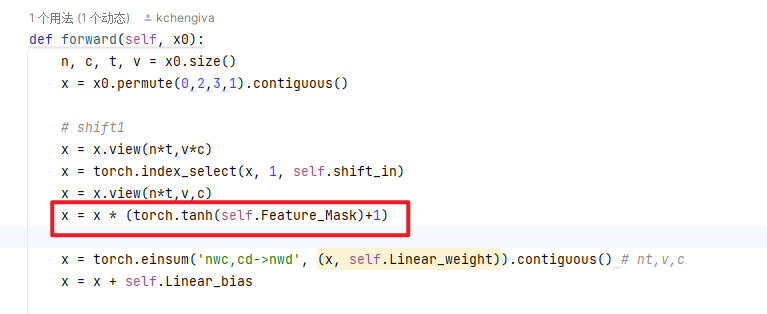
常规空间图卷积的 FLOP 为3 ×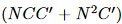 。空间移位图卷积的FLOP约为N CC′,轻了三倍以上。与仅使用三个相邻矩阵来建模骨架关系的常规图卷积相比,我们的非局部移位操作可以模拟不同通道中不同骨架之间的各种关系。Sec.4.2.1中的实验表明,我们的非局部移位GCN比常规GCN实现了更好的性能,即使常规GCN中的相邻矩阵设置为可学习[21]。
。空间移位图卷积的FLOP约为N CC′,轻了三倍以上。与仅使用三个相邻矩阵来建模骨架关系的常规图卷积相比,我们的非局部移位操作可以模拟不同通道中不同骨架之间的各种关系。Sec.4.2.1中的实验表明,我们的非局部移位GCN比常规GCN实现了更好的性能,即使常规GCN中的相邻矩阵设置为可学习[21]。
时间移位图卷积
在制定了一个轻量级的空间移位图卷积来建模每个骨架帧之后,我们现在设计了一个轻量级的时间移位图卷积来模拟骨架序列。
朴素时间移位图卷积
图形的时间方面是通过连接时间维度上的连续帧来构造的。因此,CNN中的移位操作可以直接扩展到时间域[13]。我们将通道平均划分为 2u + 1 个分区,每个分区的时间移位距离为 −u、−u + 1、· · ·, 0, · · ·, u − 1, u 分别。移出的通道被截断,空通道用零填充。移位操作后,每个帧从其相邻帧获取信息。通过将这种时间移位操作与时间逐点卷积相结合,我们得到了朴素的时间移位图卷积。
通常,在基于 GCN 的动作识别中,规则时间卷积的核大小为 9 [9, 20, 21, 34]。与常规时间卷积相比,朴素时间移位图卷积的计算成本降低了 9×。
自适应时移图卷积
虽然朴素时间移位图卷积是轻量级的,但其超参数 u 的设置是手动的。这导致了两个缺点:(1)最近的研究[11,33,38]表明,在视频分类任务中,不同的层需要不同的时间感受野。对你所有可能的组合进行详尽的搜索是棘手的。(2)不同的数据集可能需要不同的时间感受野[11],这限制了朴素时间移位图卷积的泛化能力。这两个缺点也存在于常规时间卷积中,其内核大小是手动设置的。
我们提出了一种自适应时间偏移图卷积来解决这两个缺点。给定一个骨架序列特征 F ∈ RN×T ×C,每个通道都有一个可学习的时间偏移参数 Si, i = 1, 2, · · ·, C.我们将时移参数从整数约束放宽为实数。非整数偏移可以通过线性插值计算:
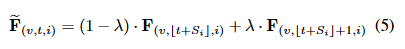
其中 λ = Si − ⌊Si⌋(λ 为Si的小数部分)。此操作是可微分的,可以通过反向传播进行训练。通过将此操作与逐点卷积相结合,我们得到了自适应时间偏移卷积。自适应时移操作是轻量级的,具有 C 额外参数和 2N CT 额外 FLOP。与逐点卷积相比,这种计算成本可以忽略不计。自适应时移图卷积的有效性和效率在第4.2.2节中得到了证明。
代码中使用了两个可偏移参数进行融合同一通道不同时间的同一个骨架节点,下面是shift_cuda_kernel.cu中的核函数的变量解析

时空移位图卷积
为了与最先进的方法[9,12,20,21,31,34]进行头对头比较,我们使用相同的主干(ST-GCN [34])来构建我们的时空移位GCN。ST-GCN主干由1个输入块和9个残差块组成,其中每个块包含一个规则的空间卷积和一个规则的时间卷积。我们将常规空间卷积替换为空间移位操作和空间逐点卷积。我们将常规的时间卷积替换为时间移位操作和时间逐点卷积。
将移位操作与逐点卷积相结合有两种模式:移位转换和移位转换,如图 4 所示。换档-转换-移位模式具有更大的感受野,通常可实现更好的性能。我们在消融研究中验证了这种现象。
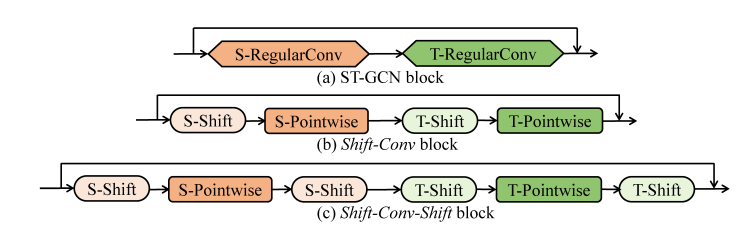
图4.组合移位操作和逐点卷积的两种模式。
实验
在本节中,我们首先进行详尽的消融研究,以验证我们提出的空间移位图操作和时间偏移图操作的有效性和效率。然后,我们将我们的时空偏移GCN与三个数据集上的其他最新方法进行比较。
数据集和试验设置
NTU RGB+D NTU RGB+D [19]包含56,880个骨骼动作序列,是评估基于骨骼的动作识别模型的最广泛使用的数据集。行动样本由40名志愿者执行,分为60个类。每个样本包含一个动作,并保证最多有 2 个主体,由三个 Microsoft Kinect v2 相机同时从不同视图捕获。该数据集的作者推荐了两个基准:(1)跨主体(X-sub)基准:训练数据来自20个受试者,测试数据来自其他20个受试者。(2)交叉视图(X-view)基准:训练数据来自相机视图2和3,测试数据来自相机视图1。
NTU-120 RGB+D NTU-120 RGB+D [15] 是目前最大的数据集,具有用于人体动作识别的 3D 关节注释。该数据集包含 120 个操作类中的 114,480 个操作样本。样本由106名志愿者用三个摄像头视图捕获。此数据集包含 32 个设置,每个设置表示特定的位置和背景。该数据集的作者推荐了两个基准:(1)跨主体(X-sub)基准:将106个受试者分为训练组和测试组。每组包含53个受试者。(2) 交叉设置(X-setup)基准:训练数据来自具有偶数设置 ID 的样本,测试数据来自具有奇数设置 ID 的样本。
Northwestern-UCLA Northwestern-UCLA数据集[29]由三个Kinect相机捕获。它包含1494个视频剪辑,涵盖10个类别。每个动作由10个演员执行。我们在 [29] 中采用了相同的评估协议:我们使用来自前两个相机的样本作为训练数据,使用来自另一个相机的样本作为测试数据。
实验设置 我们使用 SGD 和 Nesterov 动量 (0.9) 来训练模型 140 个 epoch。学习率设置为 0.1,并在纪元 60、80 和 100 时除以 10。对于自适应时移操作,平移参数初始化为-1和1之间的均匀分布。对于NTU RGB+D和NTU-120 RGB+D,批量大小为64,我们采用[21]中的数据预处理。对于西北加州大学洛杉矶分校,批量大小为 16,我们采用 [22] 中的数据预处理。消融研究中的所有实验都使用上述设置,包括我们提出的方法和常规GCN方法。
消融研究
空间移位图卷积
在本小节中,我们首先展示了空间移位图操作可以显着提高逐点卷积基线的性能。然后,我们证明了空间移位图卷积优于常规空间 GCN,计算成本降低了 3倍以上。
改进空间逐点卷积基线
为了验证空间移位图运算可以有效地扩大感受野,我们通过用简单的逐点卷积代替ST-GCN中的常规空间卷积来构建轻量级空间逐点基线。ST-GCN中的卷积,具有简单的逐点卷积。我们的空间移位图卷积 和这个逐点基线之间的唯一区别是插入空间移位操作。如表1所示,通过我们的移位图操作,可以显著改善空间逐点卷积的基线。具体来说,我们的非局部shift操作可以将NTU RGB + D X-view任务的基线提高3.6%。
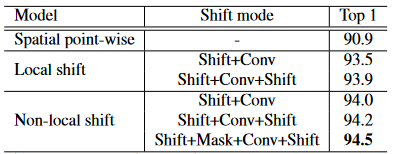
表 1.空间逐点卷积和空间移位图卷积之间的比较。
空间移位图卷积的变体 如表1所示,非局部移位图操作比局部移位图操作更有效。这种现象表明非局部感受野对于基于骨骼的动作识别很重要。对于局部移位和非局部移位模型,Shift-Conv-Shift模式优于Shift-Conv模式。这是因为移Shift-Conv-Shift模式具有更大的感受野。通过在移位特征上引入可学习的掩码,性能进一步提高。
与常规空间 GCN 的比较 在表2中,我们将空间移位图卷积与三个常规空间GCN的有效性和效率进行了比较:a)ST-GCN [34],其中相邻矩阵固定为预定义的人图,b)自适应GCN [21],其中相邻矩阵是可学习的,c)自适应非局部GCN [21],其中相邻矩阵由非局部注意模块预测。表2中的所有模型都使用相同的时间模型,因此我们可以专注于评估不同空间模型的有效性和效率。
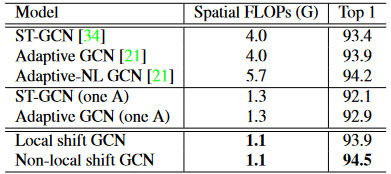
表 2.常规空间 GCN 和我们的空间移位图 GCN 之间的比较。
如表2所示,我们的局部移位GCN优于ST-GCN [34];我们的非局部移位GCN优于所有三个常规GCN。更重要的是,我们的移位图卷积比常规GCN更有效。 与ST-GCN [34]和自适应GCN [21]相比,我们的移位GCN轻了3.6倍。与引入非局部注意模块的自适应非局部GCN [21]相比,我们的移位GCN轻了5.2倍。
在表 2 中,我们还仅使用一个相邻矩阵构建了常规 GCN 的轻量级版本,后缀为“one A”,性能明显较差。这种现象表明,正则空间GCN需要多个相邻矩阵来模拟骨架之间的多样化关系,导致计算成本高。我们的非局部移位卷积可以通过轻量级逐点卷积来模拟不同骨架和不同通道之间的不同关系,这更加有效和高效。
时间移位图卷积
在本小节中,我们将空间模型固定为ST-GCN [34]的规则空间卷积,并评估了不同时间模型的有效性和效率。
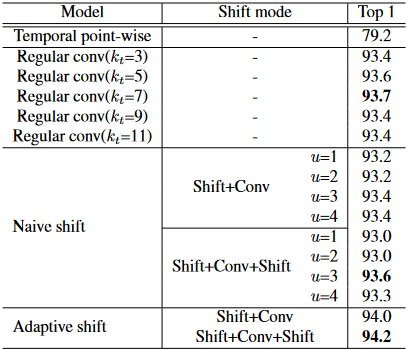
表 3.时间逐点卷积、规则时间卷积、朴素时间移位卷积和自适应时间移位卷积之间的比较。时移卷积的计算成本为kt×小于常规时间卷积,其中kt是正时间卷积的核大小。
改进时间逐点基线通过将ST-GCN [34]的常规时间卷积替换为时间逐点卷积,我们构建了一个时间逐点基线。我们的时移图卷积和这个基线之间的唯一区别是插入我们的时空移位操作。如表3所示,通过我们的时间偏移图操作,可以显著改善逐点基线。具体来说,我们的自适应时间偏移操作可以将NTU RGB + D X视图任务的基线提高15.0%。
自适应时间偏移的优越性。我们比较了三种不同的时间模型:a)规则时间卷积;b) 朴素的时间移位操作;c) 自适应时移操作。规则时间卷积和朴素时间移位操作的感受野是手动设置的,而我们的自适应时间移位操作可以自适应地调整感受野。在表3中,我们对规则时间卷积和朴素时间移位操作的最佳感受野进行了详尽的搜索。我们的自适应时移操作不需要麻烦的穷举搜索,并且优于其他两种方法的最佳结果。
自适应时间偏移的可视化
我们可视化了分别在NTU RGB + D和Northwestern-UCLA训练的自适应时间偏移参数。ST-GCN [34] 中有 10 个时态块,每个块都替换为我们的Shift-Conv-Shift模块,因此模型中有 20 个自适应时态移位操作。我们将学习到的移位参数从底层(输入层)可视化到顶层(输出层)。如图5所示,顶层的移位参数往往大于底层,这意味着顶层需要更大的时间感受野,而底层倾向于学习空间关系。请注意,在视频分类字段中,在 [33] 中进行了详尽的搜索,以查找哪一层应该使用时间卷积,他们的结论是在顶层应用时间卷积更有效。我们的自适应时移操作可以学习每一层的适当时间感受野,而无需启发式设计或手动穷举搜索。
自适应时间偏移操作的另一个优点是改进了不同数据集上的模型泛化。如图5所示,在NWUCLA数据集上训练的移位参数往往小于NTU RGB+D数据集。这是合理的,因为NTU RGB + D(71.4帧)中动作样本的平均帧数大约是NW-UCLA(39.4帧)的两倍。
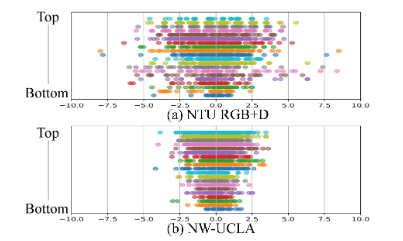
图5.自适应时间偏移的可视化。
时空移位图卷积
空间移位图卷积和时移图卷积都比常规图卷积更有效和高效。我们进行时空偏移图卷积,进一步提高性能和效率。如表4所示,时空偏移GCN的性能优于ST-GCN [34],为1.7%,计算成本降低6.5倍。
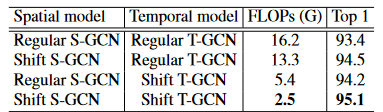
表 4.时空移位图卷积的有效性和效率.精度在NTU RGB+D X-view任务上。
与最先进的技术进行比较
许多最先进的方法利用多流融合策略。为了进行公平的比较,我们采用了与 [20] 相同的多流融合策略,即使用 4 个流。第一个流使用原始骨架坐标作为输入,称为“联合流”;第二条流以空间坐标的差分作为输入,称为“骨流”;第三和第四流使用时间维度上的差分作为输入,分别称为“关节运动流”和“骨运动流”。将多个流的softmax分数相加以获得融合分数。
我们的时空移位图卷积(Shift-GCN)有三种设置:1-流,仅使用联合流;2流,同时使用关节流和骨流;4 流,使用所有 4 个流。为了验证我们方法的优越性和通用性,在三个数据集上将移位GCN与最先进的方法进行了比较:NTU RGB + D数据集[19],Northwestern-UCLA数据集[29]和最近提出的NTU-120 RGB + D数据集[15],分别如表5,表6和表7所示。我们展示了在NTU RGB + D X-sub任务上达到高于85%的方法的计算复杂度2。
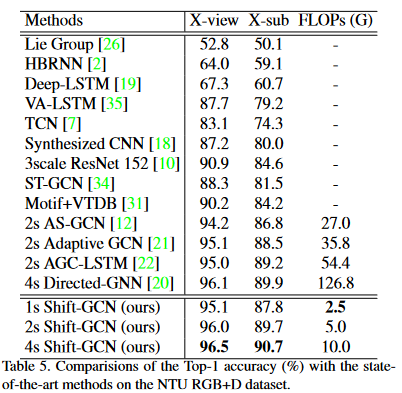
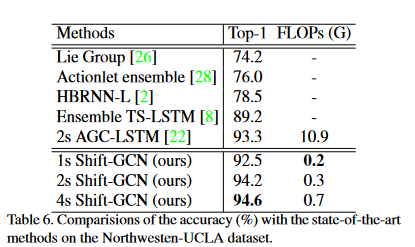
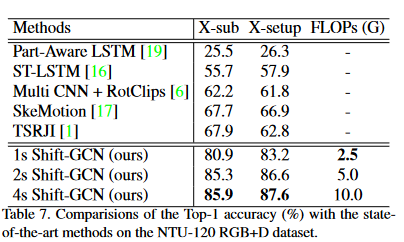
在NTU RGB+D上,1s-Shift-GCN比2s-AS-GCN [12]实现了更高的精度,计算成本降低了10.8×;2s-Shift-GCN与当前最先进的方法4s-Directed-GNN [20]相当,计算成本降低了25.4×;4s-Shift-GCN显然超过了所有最先进的方法,计算量比4s-Directed-GNN少12.7×[20]。在西北大学洛杉矶分校数据集上,我们的2s-Shift-GCN优于当前最先进的2s-AGC-LSTM [22],为0.9%,计算复杂度降低了33.0倍。在NTU-120 RGB+D数据集上,我们明显超过了之前报告的所有性能。
结论
在这项工作中,我们提出了一种用于基于骨架的动作识别的新型移位图卷积网络(Shift-GCN),该网络由空间移位图卷积和时间移位图卷积组成。我们的非局部空间移位图卷积明显优于常规图卷积,计算成本要低得多。
我们的自适应时移图卷积可以自适应地调整感受野,效率高。在三个基于骨架的动作识别数据集上,所提出的Shift-GCN明显超过了当前最先进的方法,计算成本降低了10倍以上。